トピック指向の次世代文書記述言語-DITA詳細解説1 ~ 活用方法と深層に迫る ~
1. DITAとは何か
DITA(Darwin Information Typing Architecture)は、XMLで記述する技術文書の文書型(スキーマ)および文書型の拡張方法を定義しているOASIS 標準の規格である。特に、製品解説書、操作手順書、技術情報サイトのWebページ用データ、そしてオンラインヘルプなどの技術文書を主な対象としている。 XMLの応用分野には、大きく分けると、「データ」と「文書」との二つがあるが、DITAは「文書」の系統に入る。
DITAの当初の開発元はIBMである。IBMはタグ付き文書の技術開発において、優れた伝統を持っている。XMLの前身のSGMLを開発したのはIBM に在籍していたチャールズ・ゴールドファーブである。IBMの技術文書はSGMLを用いた社内の標準形式(IBMIDDoc)に基づいて作成され、その文書が世界各地の翻訳センターで翻訳されてきた。しかし、レイアウト情報の分離、情報の再利用、他のコミュニティとの情報交換を推進するため、新たにDITAが開発されたのである(詳細については、日本IBMの吉野氏へのインタビュー記事「IBMにおけるDITAの取り組み」を参照されたい)。
DITAは1999年後半からIBMにおいて調査・開発が始まった。その成果は2001年3月に、IBMの技術情報サイトdeveloperWork に"IBM's Darwin Information Type Architecture (DITA)"という記事として公表された。そして2003年6月には、DITAのコンテンツをPDFやHTMLやヘルプなどに変換するJavaベースの DITA Toolkitsの安定版(1.1.2)がdeveloperWorksサイトから入手可能になった。
IBMは標準化団体のOASISにDITAを寄贈し、2004年3月にはOASISにDITA技術委員会(TC)が設立された。その後、OASIS規格として、DITA 1.0が2005年5月に、DITA 1.1が2007年8月に公表された。
すでに運用段階に入っているDITAであるが、DITAの特徴とは何だろうか。まず、DITAという名称から考えてみる。
DITAの「D」はDarwin(ダーウィン)の頭文字である。この「ダーウィン」は進化論で有名な、かの生物学者ダーウィン(1809年-1882年)にちなんだものである。技術文書の規格になぜダーウィンなのか不思議に思うのも当然である。このダーウィンという語はDITAの2つの特徴、つまり「専門化(特殊化)」(specialization=生物学の用語では「分化」)と「継承」(inheritance=生物学の用語では「遺伝」)をシンボリックに表している。 「専門化」と「継承」については、「6.DITAのカスタマイズ」で説明する。
DITAとは何かを端的に表しているのは、むしろ後半のInformation Typing Architectureという表現である。Architectureは文字どおり「体系」である。それは情報(Information)の型付け(Typing)を行う体系である。DITAを使えば、情報型に基づき、技術情報の執筆(オーサリング)からPDFやHTMLなどの最終出力に至るまでを、一連の設計原理にしたがって体系的に構築することができる。
したがってDITAは単なるXMLの文書型を定義したものではない。技術情報の制作工程全体を視野に入れ、これまでの様々なコンテンツ技術や手法 を参考にして規格化された、コンテンツ管理の統合的な情報スキーマを提供するXML応用技術である。
2. DITAの構造とトピック指向
DITAの基本構造となるのは、次の二つである。
トピック(topic)
マップ(map)
トピック(topic) はDITAにおける情報の構成単位である。トピックはコンテンツの本体で、それ自体で意味を成す情報の単位であり、また情報の再利用の単位となる。DITA文書は基本的にトピックの集合であると考えることもできる。
一方、マップ(map) は、最終的に配布する制作物の種類や形態に応じて、トピックをどのように並べるか、つまりトピックの構成方法を指示するものである。(図1)
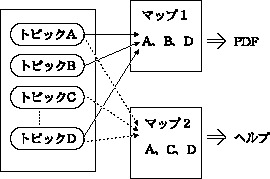
図1:トピックとマップの関係
同じトピック群を基にしていたとしても、媒体や用途によってはトピックの並べ方や取捨選択が変わることがある。たとえば、印刷するマニュアルのための版下を用意する場合と、ヘルプ・ファイルを用意する場合とでは、内容や構成が異なるだろう。また、製品仕様が国別で多少異なる場合は、使用するトピックを別々のマップで管理することでその差異を吸収できる。
技術文書をトピックという比較的小さな単位に分割して記述するというトピック指向(topic- oriented)は、DITAの最大の特徴である。これは単にXMLで記述する文書型が変更されたという問題ではなく、執筆(オーサリング)のスタイルが変わることを意味している。トピックはそれ自体で記述内容が完結し、また再利用できるような内容になっていなければならない。
▲このページのTOPへ






