隠されたニーズを引き出すXMLデータベース 「第3回 その必要と条件」
著者:ピーデー 川俣 晶
前回までのあらすじ
この連載では良いニュースと悪いニュースを語っている。
良いニュースとは、IT業界にはこれから開拓すべき膨大な未開の分野が存在することである。それによって、ベンダーやシステムインテグレータは新しいビジネスを行うことができるし、ユーザはこれまでシステム化できなかった分野を効率化できる可能性を得ることができる。特にIT化できる処理はすべてIT化済みで、これから何を作っていけばよいのかと考えているようなシステムインテグレータやユーザにとっては、良いニュースといえるだろう。
悪いニュースは、上記と表裏一体になるものである。膨大な未開の分野が残されているということは、従来の技術や方法論では上手く扱えない領域が存在することを意味する。つまり、それらの分野に乗り出していくためには、それに適応するための新しい技術や新しい方法論が必要とされる。
この連載の「第1回:その必然と当然」では、どのようなニーズがいかにして取りこぼされているかを紹介した。様々な話題を紹介したが、それを一言で要約すると、「変化への適応力が要求されるニーズ」となる。従来、システム開発に使われていた技術、特にRDBは変化に弱いのである。
この問題を解決するために、XMLデータベースを用いるという方法が提案されている。そこで、連載の「第2回:その要求と分類」では、XMLデータベースの紹介を行った。XMLデータベースと呼ばれるソフトは、実は様々な機能や制約を持った多種多様な種類に分かれることを説明した。単にXMLデータベースを使えばよいというわけではなく、個々のXMLデータベースの特徴をよく調べないと、目的とする用途に使えないという事態も発生するわけである。
そして今回は前2回をふまえ、第1回で紹介したニーズをXMLデータベースで満たすためには、第2回で紹介したXMLデータベースの様々な特徴のうち、どれに重点を置けばよいかを説明していく。
ニーズを満たす具体的な手順が見えてくれば、新しいビジネスの開拓も容易だろう。
それはニーズから見い出された
最初に踏まえねばならないのは、これが技術主導の話題ではなくニーズ主導の話題だということである。つまりXMLデータベースという素晴らしい最新技術が登場したので、それを使って何か凄い応用を実現しましょう...、という話ではないのである。
XMLデータベースの有無とは関係なく「ニーズはそこに存在する」のである。そのニーズの一部は潜在的なものであり、そこにあることに誰も気付いていないかもしれない。
別の一部は顕在化していて、情報システム化したいと期待されつつ失敗を繰り返してきたかもしれない。あまりに失敗が多く、失意の断念によって忘却されてしまったニーズもあるだろう。
実はシステムインテグレータにとって、このようなニーズが存在することはさほど大きな問題ではない。なぜなら、そのようなニーズは避けて通り、容易にシステム構築が可能なニーズだけを拾い上げてビジネスを行うという選択があるからだ。
しかしニーズを抱えるユーザ側は、ニーズを避けて通ることができない。まさに自分が抱えるニーズだからである。システム化を諦めなかったユーザ達は、ニーズに適した技術の出現を心待ちにしていた。
そういう状況で出現したのがXMLであり、XMLデータを格納することができるXMLデータベースだったといえる。
つまり、彼らはXMLデータベースを心待ちにしていたのではない。彼らのニーズを満たすことができる「何か」を待っていたのである。
裏を返せば、この事実はXMLデータベースであればニーズを満たせるというような楽な話ではないことがわかる。相互に置き換えることができないほど多様なXMLデータベースの中には、ニーズに適合するものもあれば、適合しないものもあるだろう。
さらにいえばユーザ側のニーズも当然均一ではない。個々のユーザごとに要求が違うという状況もあるだろう。ゆえにニーズとXMLデータベースの組み合わせは個別の状況ごとに慎重に見ていかねばならない。
そのような話題であるということを踏まえて続きをお読みいただきたい。これはXMLデータベースを褒め称える記事ではなく、「ニーズと照らし合わせてどのようなXMLデータベースを選択していくべきかの基本的な心構え」を書いた記事である。
XMLデータベースは唯一の選択肢なのか
ここまでの話で、以下のような疑問を感じた読者も多いと思う。
もしニーズこそが重要であり、XMLデータベースは単にニーズを満たすために選ばれたものに過ぎないとしたら、ニーズさえ満たせればXMLデータベース以外のデータベースを使ってもよいのではないだろうか。
この疑問は正しい。
実際問題として、ニーズさえ満たせればよいのであって、どうしてもXMLデータベースでなければならない必要性は存在しない。
例えば、世の中には様々な種類のデータベースが存在する。RDBの他にオブジェクトデータベースなどの選択肢がある。それらと比較してXMLデータベースが採用される理由は、それがよりニーズに近いからに過ぎない。
ならば、同じぐらいニーズに近いデータベースを創作することに成功したら、XMLデータベースの代わりにそれを使ってもよいのではないだろうか?
その答えは「否」である。
XMLデータベースに格納されるデータはXMLデータである。XMLデータを扱うためのツールや技術は豊富に存在する。つまりXMLデータを入力するためのフォーム作成を支援するツールや、XMLデータを綺麗に書式整形されたPDFファイルに変換するためのツールなどが揃っているからこそ、XMLデータベースは実用性が高いのである。
同程度に周辺環境が整備された実績あるデータベースについて論じるならともかく、まったく新しい種類のデータベースを創作しても同じ水準の使い勝手は得られない。
その点にこそ、XMLデータベースである必然性が存在するのである。
ニーズを満たすための条件
さて、ここからが本題である。
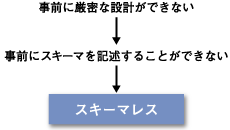
従来の技術では上手く適応できなかったニーズの多くは、事前に厳密な設計ができないデータを持つという共通の特徴がある。
「事前に厳密な設計ができない」という状況は、さらに2つに分けて考えられる。
1つは、設計が完了できないままシステムの開発を行わねばならない場合や、開発中に変更要求が入る場合である。このようなケースでは開発中に設計は変化を続け、システムが完成した時点で設計が固まることになる。
もう1つは、システムの完成後にも変更に対する要求が随時発生する場合である。このようなケースでは、運用しながら新しい種類のデータを付け加えていくことになる。つまり運用中に設計が変わるということだ。
さてソフトウェアのライフサイクルというものを考えると、長期にわたって運用が続けばシステムに対する変更要求は必ず発生する。このような要求を踏まえて考えるなら実は2つに分類することは意味がなく、すべてのシステムは「システムの完成後にも変更に対する要求が随時発生する」と見なすことができる。つまり、すべてのシステムは「事前に厳密な設計ができない」ということになる。
もちろん、このような認識は実用的ではなく、変化に対する要求が小さなシステムでは「事前に厳密な設計ができる」と見なして問題ないケースも珍しくない。そして事前に厳密な設計ができれば、開発の効率はよいものになる。この条件に該当するシステムは、従来からの技術や開発方法論で問題なく扱えるので、この記事の対象外である。
ここで、話を本題に戻そう。
XMLデータベースにおいて、データベースの設計とはスキーマを記述することと見なすことができる。つまり「事前に厳密な設計ができない」とは、「事前にスキーマを記述することができない」ということを意味する。
ここが今回の第1の山場である。
すでに述べた通り、従来からの技術や開発方法論で取りこぼされてきたニーズの多くは「事前に厳密な設計ができない」という特徴を持つ。それは「事前にスキーマを記述することができない」ことを意味する。ということはデータベースを作成する際にスキーマを要求するXMLデータベースは、このようなニーズに対応するために不十分であることを意味するのである。
必然的に本連載の「第2回:その要求と分類」で解説したXMLデータベースの中で、「スキーマは必須」という特徴を持つソフトは適応しないことになる。
また「スキーマがあれば性能が向上する」というソフトは、スキーマ抜きでは性能が十分に発揮できない可能性がある。個々のニーズへの適応度は、性能の評価次第といえるだろう。
よって最善の選択はスキーマ不要(スキーマレス)のXMLデータベースとなる。スキーマなしで最善の性能を発揮させるよう設計されたスキーマレスのXMLデータベースは、まさに「事前に厳密な設計ができない」データを扱うのに最適である。
▲図1:第1のポイントはスキーマレス
もう1つの重要なポイント、それはサイズ
従来の技術では上手く適応できなかったニーズを満たす条件として「スキーマレス」という特徴が浮かびあがってきた。
だが、まだ十分ではない。
技術主導とニーズ主導がぶつかり合う場面では、もう1つ外せない重要なポイントが存在する。
技術を扱う立場に立ったときには、RDBのような主要なデータベースとXMLデータベースやオブジェクトデータベースなどの特殊なデータベースを比較した場合、両者に歴然とした相違があるという認識を持つ場合がある。
より具体的にいえば、主要なデータベースとは大量のデータを高速に処理する能力や高い信頼性、可用性などを持つものであり、特殊なデータベースはまさに特殊なニーズに適応するために、処理性能や信頼性を犠牲にしたものである...という認識である。
このような認識は、技術者の観点から見れば、あながち間違いとはいえない。特殊なデータベースを使うためには、それなりの代償が要求されるのである。
しかしニーズ主導という立場に立ったときには、まったく違う認識が浮上する。実は「事前に厳密な設計ができない」データは、「設計できる」データよりも量が少ないと決まったものではないし、信頼性や可用性が低くてもよいという話でもない。つまり、技術主導の場合には当然許されたはずの性能低下という代償は許されない。
前回紹介したXMLデータベースの世代による分類とは、まさにこれを意味しているといえる。第1世代のXMLデータベースとは技術主導のデータベースであり、性能や信頼性が劣っていてもやむを得ないという態度のものが多かった。
しかし第2世代のXMLデータベースはニーズ主導であり、性能や信頼性の面で妥協しないという態度を持つものが多い。
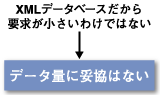
ここで特に重要な意味を持つのはデータベースのサイズである。大量のデータに対して高速のクエリを実行できねば、そもそも稼働させることすらできないのである。XMLデータベースを採用し、運用するという問題に対して立ちはだかる最大の敵はサイズだといってもよいだろう。
ここが今回の第2の山場である。
つまりXMLデータベースだからといって、データ量に妥協はない。必要とされるサイズのデータに対して、高速なクエリが実行できるXMLデータベースでなければ、採用する意味はない。
▲図2:第2のポイントはサイズ
では一般論としてXMLデータベースはRDBと同程度のデータ量が扱えればよいのかというと、そうではない。実は「RDBよりも大きなXMLデータベース」に対するニーズも存在する。
それは、データベースを集めた大データベースの構築である。
RDBよりも大きなデータベース
ナレッジマネジメントなどの分野では、組織内に散在するいくつものデータベースを統合した大データベースを構築し、それに対して検索を行うことで、組織に対して横断的な情報を把握するという作業が提案されることがある。
このようなニーズに適合する大データベースの構築は、実は難しい。
あらかじめ統合されることを想定せずにバラバラに構築されたデータベースは、当然データの整合性などをきちんと意識して作られてはおらず、データベースを寄せ集めてもなかなか上手く噛み合わない。事前に厳密な設計を行わねばデータベースを構築できないRDBなどでは、上手く噛み合わないことが設計不能という結論につながりかねない危うさを持つ。
しかしスキーマレスのXMLデータベースでは、事前の設計が必要ない。設計しなくてよいということは、どのようなデータでも自由に入れることができることを意味する。つまり、整合しないデータは整合しないまますべてあるがままに1つのデータベースに入れることができる。
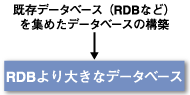
そして仮にそのようなデータベースを構築したとすると、そのデータベースのサイズは個々のデータベースのサイズよりも大きなものになってしまう。
ここが今回の第3の山場である。
複数のRDBを集めた大データベースをスキーマレスのXMLデータベースを用いて構築した場合、XMLデータベースのサイズは個々のRDBよりも大きなものになる。つまりXMLデータベースに要求されるデータ量は、RDBよりも大きくなるとすらいえるのである。
例えば第2世代XMLデータベースのNeoCore XMSでは数百ギガバイトまで使用可能とされ、他の第2世代製品ではテラバイト級というコピーを宣伝に使用しているケースまであるが、これは過大な許容量ではない。
▲図3:第3のポイントはより大きなDB
サーバの台数を減らせ
XMLデータベースに要求されているのは、単に大きなデータを高速にクエリする能力ではない。性能が足りなくなった場合にはサーバを増設して改善するスケールアウト能力は必須の機能といえる。
しかし、だからといって無限にサーバを増やし続けるわけにもいかない。確かにサーバの値段は劇的に低下しているが、サーバを運用するにはそれなりの管理コストが発生するのである。それゆえに、XMLデータベースにはサーバの台数を増やさずに大量のデータを高速処理する能力が求められる。
このことは、本連載で扱うニーズがごく普通の組織のごく普通の業務の中にも多数眠っていることから考えても容易に理解できるだろう。
例えばオフィスの片隅に置かれたサーバ1台で業務をまかなっている組織に、いきなりサーバを10台置けばこの業務も情報システム化できます...といっても物理的に無理があるだろう。
サーバの台数を増やさずにクエリを高速処理する性能も、XMLデータベースに要求される(これが今回の第4の山場となる)。

▲図4:第4のポイントは性能
コスト意識を持とう
実は、ここで述べたような条件を満たすXMLデータベースソフトは高価なものが多い。
最先端の高度なソフトといえば、オープンソースで優秀なソフトが無料で入手できる...という印象を持っている読者もいると思うが、残念ながら多くの利用者に待望されつつも、決定版と呼べるだけのオープンソースのXMLデータベースはまだ出現していない。
では製品として提供されるソフトはというと、いずれも最低でも数百万円からという値段が付いている。
とはいえそれがもたらす効能からすれば、この価格はけして高いものではない。むしろ、安いとすらいえるだろう(これが今回の第5の山場となる)。
もちろん価格は安いに越したことはない。エントリー価格がこれでは試すこともできないであるとか、小規模案件で試しに使ってみることもできない...といった不満はあり得るだろう。
しかし試用については、無料で入手できるサンプル版を提供する場合などもあり、それらを活用することができるだろう。特にNeoCoreXMSの無料フリー版となるXprioriは、データベースサイズや商業利用に対する制限はあるものの、自由に使って試すことができるのでお勧めである。

▲図5:第5のポイントはコスト
さて、XMLデータベースの価格に関しては、利用者が増えればそれに応じて下がってくるのではないかと考えている。一度使うと手放せないともいわれるXMLデータベースなので、利用者が増えることは間違いないと考える。現在は、まだ高価すぎるケースであっても、将来的にはXMLデータベースを採用できる時代が来るだろう。
終わりに
3回にわたってXMLデータベースについて解説してきたが、結論はシンプルである。
第2世代のスキーマレスXMLデータベースは、これまで顧みられることがなかった多くの潜在的なニーズを満たし得る可能性がある。
そのようなニーズは、おそらくRDBですでに満たすことができたニーズよりも多いかもしれない。つまり、まだまだこれからである。
その際、最も重要なことは、変化や曖昧さといった人間や社会の特徴を正面から受け止めてシステムを構築することである。変化や曖昧さを排除しようとしてはいけない。それは、当然あるべきシステムの一部なのだ。
かといって秩序を打ち立てようとする努力を放棄し、すべてを成り行きに任せる堕落も避けねばならない。それは破滅の最短コースである。秩序にも混沌にも堕落せず、その中間領域に踏みとどまることでのみ、スキーマレスのXMLデータベースはその素晴らしい効能を発揮してくれるだろう。
▲このページのTOPへ






